
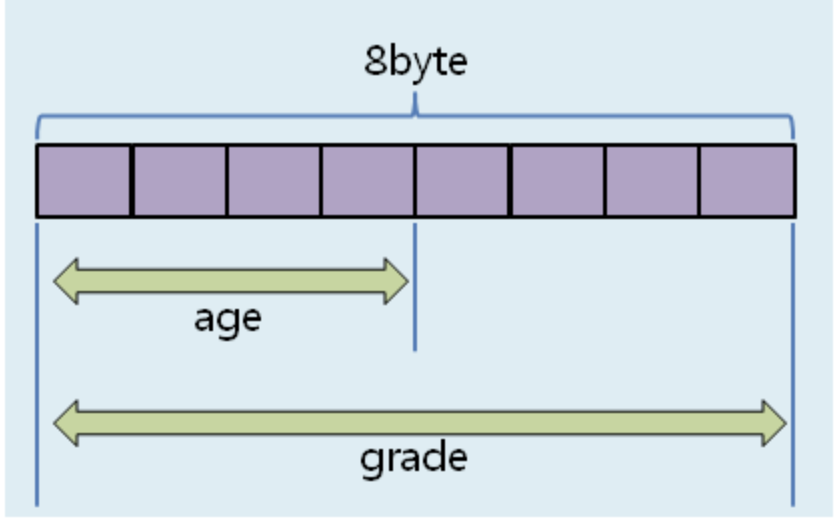
Data Types
Chapter6 - Data Types
배열
-
배열의 종류
- 직사각형 배열 - 모든 행, 열들이 동일 개수의 원소들을 포함하는 배열
- 톱니형 배열 - 행들의 크기가 동일할 필요가 없는 다차원 배열 - C와 JAVA, PYTHON는 톱니형 배열
→ 톱니형 배열은 다차원 배열이 실제로는 배열을 포함하는 배열일 때 가능
→ 행렬을 1차원 배열들을 포함하는 배열로서 보는 것
-
슬라이스
- [중요] 슬라이스는 새로운 데이터 타입이 아니고 같은 데이터 타입이다.
→ 배열의 부분을 한 단위로 참조하기 위한 메커니즘
- [중요] 슬라이스는 새로운 데이터 타입이 아니고 같은 데이터 타입이다.
-
배열의 발전 단계
- 초기 배열에서 주요 진보 : 동적 배열, 슬라이스
- 최근 주요 진보 : 연상 배열(연관 배열) → Python - dict
-
배열 타입의 구현
- 배열을 구현하는 것은 기본 타입을 구현하는 것 보다 상당히 더 많은 컴파일 노력이 요구됨
- 배열 원소의 접근을 허용하는 코드는 컴파일 시간에 생성되어야 함
- 생성된 코드는 실행 시간에 배열에서 특정 원소들의 주소를 계산할 수 있어야 함
- 1차원 배열 → 주소(list[k]) = 주소(list[하한]) + ((k - 하한) * 원소 크기)
→ 원소 크기는 바인딩된 데이터의 타입에 따라 다름 - int, char …
→ 하한은 0인 언어가 대부분(index의 시작이 0이란 뜻) - 다차원 배열 → 1차원 배열보다 구현하기 복잡함
→ 두 개 이상의 차원을 갖는 데이터 타입의 값들을 1차원 메모리로 사상되어야 함
→ 사상 방법 → 행 우선 순서, 열 우선 순서
행 우선 순서 - 첫 번쨰 행의 원소들을 먼저 저장한 뒤, 다음 행의 원소들을 저장하는 형태 → 대부분의 언어에서 사용
열 우선 순서 - 첫 번쨰 열의 원소들을 먼저 저장한 뒤, 다음 열의 원소들을 저장하는 형태 → Fortran에서 사용 - 다차원 배열
주소(a[i, j]) = 주소(a[row_lb, col_lb]) + (((i - row_lb) * n) + (j - col_lb) * 원소 크기)
주소를 찾고 → 값을 가져옴
덧셈과 곱셈 연산은 런타임때 수행되어야 한다.
-
연상 배열
- 원소 개수와 동일한 개수의 키 값들로 인덱싱되는 순서를 갖지 않는 데이터 원소들의 모임
- index를 가지고 저장할 필요가 없으니 key값이 필요함
- 각 원소는 (key, value)라는 쌍이 됨
- python 에서는 직접 지원, JAVA에서는 표준 클래스 라이브러리로 지원
- 연상 배열을 원소들에 대한 탐색이 요구되면 배열보다 훨신 좋음
→ 원소를 접근하는데 사용되는 묵시적인 해시 연산이 매우 효율적이기 때문
→ 리스트의 모든 원소들에 대해 오퍼레이션을 수행해야 한다면, 배열이 더 효율적임
자료구조
-
레코드
- 개개의 원소들이 이름으로 식별되고, 그 구조의 시작부분으로부터 오프셋을 통하여 접근되는 데이터원소들의 집단체
- 대부분의 언어에서 필드(레코드의 원소) 참조를 위해서 도트 표기법을 사용
- c, c++, c#에서 레코드는 struct (구조체 타입) 으로 지원됨
- python, ruby에선 딕셔너리 or 해시로 구현될 수 있음
- Java에서는 데이터 클래스로서 정의될 수 있음
-
튜플
- 레코드와 유사한 데이터 타입이지만, 원소들이 명명되지 않는다는 차이점을 가짐
- python 에서는 변경 불가 튜플 타입을 제공
→ 배열을 함수의 매개변수로 전달해야 하지만, 그 함수가 배열의 내용을 바꾸지 못하도록 하기를 원할 때, 사용
-
리스트
python에서의 리스트
- python에서의 리스트 데이터 타입은 배열로서도 역할을 수행함
- 다른 언어들과 달리 python에서 list는 변경 가능함 [중요] - 문자열, 튜플은 변경 불가
- 리스트에는 임의의 데이터 값이나 객체를 포함할 수 있음
- 리스트 포괄(리스트 함축)이라 불리는 배열을 생성하기 위한 강력한 메커니즘을 포함함
→ ex. [x for x in range(1, 10, 2)]
자바의 arratList도 실제로 리스트로 볼 수 있음
-
공용체
- 그 변수가 프로그램 실행 중, 다른 시기에 다른 타입의 값을 저장할 수 있는 타입
- c, c++에서는 타입 검사에 대한 언어 지원이 없는 공용체 구조를 사용
→ c, c++이 강타입 언어가 아닌 이유중 하나 - 공용체는 구조체와 달리 멤버 변수중 메모리 할당량이 가장 큰 변수 하나의 공간만 할당 후 공유
포인터
-
포인터 타입과 참조 타입
- 포인터 타입
→ 변수가 메모리 주소와 특수 값(null)로 구성되는 값들의 범위를 갖는 타입
→ null은 유효한 주소가 아니며, 포인터가 메모리 셀을 참조하는데 현재 사용될 수 없음을 나타내는데 사용- 포인터의 두 가지 사용 용도
→ 포인터는 어셈블리어 프로그램에서 빈번히 사용되는 간접 주소지정 형태로 사용
→ 포인터는 동적으로 할당되는 힙이라 불리는 기억공간 영역의 한 위치를 접근하는데 사용 - 힙 동적 변수
→ 힙으로부터 동적으로 할당되는 변수들을 의미
→ 이 변수들은 흔히 이들과 연관된 식별자를 갖지 않음
→ 따라서, 포인터나 참조-타입 변수들에 의해서만 참조될 수 있음
→ 이름이 없는 변수 = 무명 변수 - 포인터 연산
→ 포인터 타입을 제공하는 언어가 제공하는 두 가지 기본적인 포인터 연산- 배정 연산 - 포인터 변수의 값을 어떤 주소로 설정하는 것
- 역참조 연산 - 포인터 변수에 바인딩된 메모리 셀이 가리키는 메모리
→ 주소로 가서 주소에 있는 값 → 몇 byte를 읽을까가 중요
→ c 언어에서 역참조 연산의 예시 - j = *ptr // 역참조 연산
- (*p).age // 역참조 후 ‘ . ‘ 으로 필드 참조
- p→age // ‘→’로 역참조와 필드참조를 한꺼번에 처리
- 힙 메모리 관리는 위해 명시적인 할당 연상 수행 - malloc() 사용, 객체 지향언어는 new를 사용
-
포인터의 문제
허상 포인터[dangling pointer] 와 분실된 힙-동적 변수[garbage]
-
허상 포인터
→ 허상 포인터 or 허상 참조는 이미 회수된 힙-동적 변수의 주소를 포함하는 포인터를 의미
→ 위험한 이유들- 가리키고 있는 기억장소 위치가 어떤 새로운 힙 동적 변수에 다시 할당되었을 경우, 새로운 변수의 타입과 이전 변수의 타입이 일치하지 않을 수 있음.
- 동일한 타입이라고 하더라도, 새로 할당되는 값 v는 이전 포인트의 역참조된 값과 무관할 뿐더러, 허상 포인터를 이용하여 값을 변경하면, 새로 할당된 값 v는 메모리 상에서 사라질 수 있음
- 허상 포인터가 가르키고 있는 메모리 위치를 기억공간 관리 시스템에서 임시로 사용하는 경우(가용 기억공간 블록들의 체인에 대한 포인터로 사용하고 있는 경우), 기억공간 관리 시스템의 동작을 훼손할 수 있음
int *ptr1; int *ptr2 = (int *)malloc(sizeof(int) * 100); ptr1 = ptr2; free(ptr2); // ptr1은 허상 포인터 -> 가르키고 있는 힙 기억공간이 반환되었음
-
분실된 힙 동적 변수
→ 사용자 프로그램에서 더 이상 접근될 수 없는 할당된 힙 동적 변수를 의미
→ 이 변수를 흔히 쓰레기(garbage) 라고 부름
→ 이 변수들은 원래 목적에 따라 사용될 수 없고, 새로운 용도로 프로그램에게 다시 할당될 수도 없기 때문int *p1; int p2; p1 = (int *)malloc(sizeof(int) * 100); p1 = &p2; // 이제 malloc()으로 할당받은 힙 동적 변수는 쓰레기가 됨.→ 이렇게 할당된 부분을 분실할 경우 → 메모리 누수(mem leakage)
-
-
c, c++ 의 포인터
→ 포인터는 주소가 어셈블리어에서 사용되는 것과 동일한 방식으로 사용될 수 있음
→ 포인터는 임의의 변수를 가르킬 수 있으므로, 극도로 유연하지만, 조심스럽게 사용해야함
→ BUT, 허상 포인터와 가비지에 대한 어떤 해결책도 제공하지 않음
→ 게다가, 포인터에 산술 연산이 사능하도록 허용int *ptr; int list[10], temp; ... ptr = list; temp = *(ptr + 1);→ 포인터는 함수를 가르킬 수도 있음 - 함수 포인터
→ void 포인터를 지원하며 이를 포괄형 포인터라고 부름 (이는 역참조는 불허함 역참조할 크기를 모르기 때문) -
참조 타입
→ 포인터와 유사하나, 한 가지 중요하고 근본적인 차이점이 있음
→ 포인터는 메모리의 주소를 참조하는 것에 비해, 참조 변수는 메모리의 객체나 값의 주소를 참조함
→ 그 결과, 주소에 대해서 산술 연산을 하는 것은 자연스럽지만, 참조에 대해서 산술 연산을 하는 것은 무의미함Ex) JAVA
String str1; str1 = "TEST"; // 처음에는 str1이 null로 설정됨 // 다음 배정문에 의해 str1은 String객체를 참조하도록 설정됨→ JAVA 클래스 인스턴스들은 묵시적으로 회수됨 (free 연산자가 없어서 허상참조가 있을 수 없음)
따라서, 허상 참조 (dangling reference)가 존재할 수 없음 → 대신 가비지가 많아짐 → 가비지콜렉터
→ python의 모든 변수는 참조 변수임
이러한 변수들은 항상 묵시적으로 역참조 됨 -
포인터와 참조 타입의 구현
→ 대부분의 언어에서 포인터는 힙 기억공간 관리에 사용됨
→ JAVA, PYTHON의 참조 변수도 마찬가지임-
포인터와 참조의 표현
→ 대부분의 대형 컴퓨터에서, 포인터와 참조는 메모리 셀에 저장되어 있는 한 개의 값임
→ But, 초창기 마이크로컴퓨터에서 주소는 두 개의 부분으로 구성 → 세그먼트, 오프셋
→ 따라서, 포인터와 참조는 2개의 16비트 셀로 구현됨 → 총 32비트(4byte) 요즘은 64비트 -
허상 포인터 문제의 해결책
→ 현재까지 제안된 것 중, 가장 좋은 해결책으로 “묵시적 회수” 방법이 존재
- 프로그래머를 거치지 않고 힙 동적 변수를 회수하는 방법
- 힙 동적 변수가 더 이상 유용하지 않을 때 실행 시간 시스템이 묵시적으로 회수
- 허상 포인터가 생성되지 않음 → JAVA, LISP 등에서 사용 -
힙 메모리 관리
- 쓰레기 회수에 대한 여러가지 다른 방법이 존재함
1) 참조 계수기의 회수 시점
- 회수가 점차적으로 이루어지며, 접근될 수 없는 셀들이 생성될 때 수행됨
- 조기 접근 방법 2) 표시 - 수집 방법의 회수 시점
- 가용 기억공간이 부족할 때만 회수가 실행됨
- 지연 접근 방법
- 쓰레기 회수에 대한 여러가지 다른 방법이 존재함
1) 참조 계수기의 회수 시점
- 참조 계수기 방법
-
동작 개요 모든 셀에 대해서 현재 자신이 가르키고 있는 포인터들의 개수를 저장하는 계수기를 유지함
포인터가 셀로부터 분리될 때, 참조 계수기 감소 연산 수행
참조 계수기의 값이 0이면, 셀이 쓰레기이므로, 가용 공간 리스트에 반환 가능 -
문제점 기억공간 셀들의 크기가 상대적으로 작다면, 계수기에 의해 요구되는 공간 부담 존재
계수기의 값을 유지 관리하기 위한 실행 시간 필요
셀들의 모임이 순환적으로 연결되어 있다면 문제가 복잡함
→ 순환 리스트에속한 셀은 적어도 1의 참조 계수기를 갖기 때문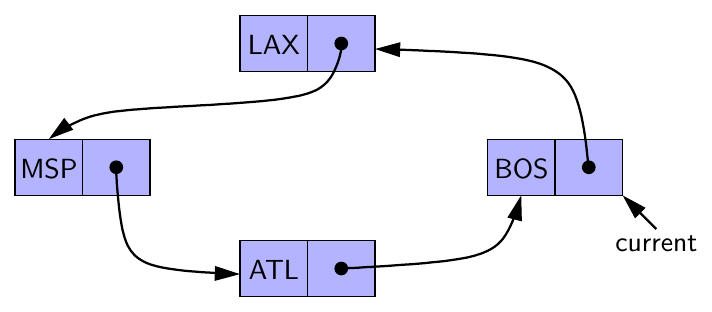
→ 해결책이 제시되었지만, SKIP
-
장점 점차적으로 실행되기 떄문에, 응용 프로그램 실행에 상당한 지연을 초래하지 않음
-
- 표시-수집 방법
-
동작 개요
실행시간 시스템은 요구될 때 기억공간 셀들을 할당하고, 필요할 때 포인터들을 셀들로부터 분리시킴
이러한 과정은 기억공간 회수에 상관하지 않으면서 (쓰레기가 누적되는 것을 허용 하면서) 가용 기억공간의 모든 셀들이 할당될 때까지 이루어짐
이 시점에서, 표시수집 프로세스는 힙 공간에서 떠다니고 있는 모든 쓰레기를 모으기 시작
쓰레기 수집 과정이 용이하도록, 한 공간의 모든 셀은 그 수집 알고리즘에서 사용되는 여분의 지시자인 비트나 필드를 가짐 -
문제점
이 방법은 너무 드물게 수행됨
그것도 프로그램이 거의 모든 힙 기억공간을 사용하였을 경우에만 수행
→ 한 번 동작하기 시작하면 상당히 많은 시간이 소요
→ 점차적 표시-수집 절차 제안
- 점차적 표시 수집 방법은 메모리가 소진되기 훨씬 이전에 더 빈번하게 수행
- 따라서, 응용 프로그램의 실행 지연을 단축시킴
-
-
Leave a comment